ChatGPT 가 탄생한 이후 LLM의 열기는 아직도 뜨겁다. 특히 기업에서의 LLM 도입은 더 많은 사례와 더 많은 종류의 모델, 그리고 그를 지원하는 다양한 소프트웨어가 생겨나면서 더 견고해지는 시스템 아래 상승곡선을 타고 있는 듯하다.
이에 나도 자연스럽게 LLM 에 관심이 계속 가고 있는데, 관련 자료를 읽을 때마다 가장 흥미로운 동시에 이해하기 어려운 부분이 바로 architecture 이다. "거대 언어 모델"이라는 명칭이 암시하는 매우 복잡한 구조도 여러 종류가 있는데 저마다의 강점과 단점이 명확하다.
오늘 이 포스트에서는 Mixtral 7x8b 모델의 기반으로 유명한 구조, Mixture of Experts(MoE)의 핵심을 알기 쉽게 설명하고자 한다.
참고로, 수식이나 통계적 이론은 최대한 말로 풀어 설명하였다.
- Dense vs Sparse
MoE의 핵심은 바로 sparsity 에 있다. 보통의 모델에서는 input token을 처리할 때 모델 내에 있는 모든 파라미터를 사용한다. 떄문에 추론 시의 속도와 비용은 모델의 크기에 비례하게 된다. 이와 반대로 MoE에서는 모델의 일부 파라미터만 사용하게 된다. 예를 들어 Mixtral 7x8b의 경우 전체 파라미터 수는 47 billion 이지만, 실제 추론 시에 사용되는 파라미터는 - 이를 active parameter 라고 한다 - 12.9 에 불과하다.
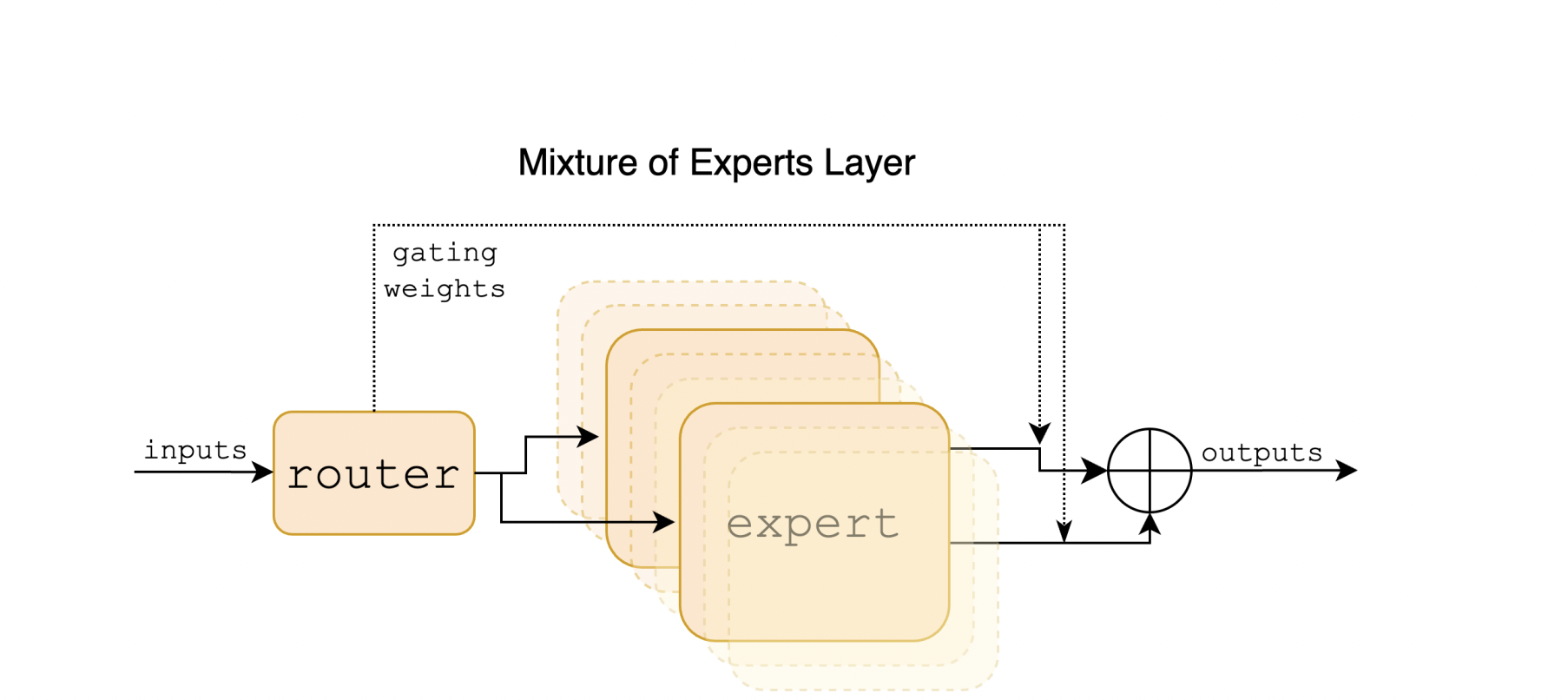
이것이 가능한 이유는 바로 expert 구조 때문이다. 대부분의 모델은 각 layer 에 feed forward network 한 개가 있고 그 network 안에 모든 파란미터가 사용되어 dense 하다고 불린다. 반면 MoE의 경우, 각 layer 에 여러 개의 network 들이 있으며, 각각의 network을 expert라 부른다. 그리고 각 input token은 n개의 expert 중 가장 적합한 output 을 내줄 top k 개에게만 보내줘 처리되어 해당 layer 에서의 ouput은 두 expert 의 ouput의 가중합이 된다. 즉, 이 input token은 선택된 모델의 모든 파라미터가 아니라 k 개의 expert 안에 있는 parameter 에만 노출되는 것이다. minstral 7x8b 의 경우, 이름에서 알 수 있는 8개의 expert 가 있고 각 input token은 그 중 두 개의 expert로만 보내진다고 한다.
만약 n 개의 expert 중 top k 개만 '활성화'된다면, 이 top k 개를 선정하는 요소도 분명 존재해야 할 것이다. 이를 담당하는 부분이 바로 router다. 실제로 이 router에서 사용되는 함수가 모델의 전체적인 성능에 많은 영향을 끼친다고 한다.
가장 흔하고 기본적인 함수는 바로 softmax 이다.
- 성능
MoE 의 최대 강점 중 하나는 실제로 token 을 처리하는 active parameter의 수가 현저히 적지만 그에 비해 월등한 성능을 낸다는 것이다. Minstral 7x8b 를 발표하면서 낸 논문에서 common sense reasoning, world knowledge, reading comprehension, math를 포함한 다양한 영역에서 해당 모델을 라마2 70b 와 비교하였는데, 대부분의 벤치마크에서 우월한 성능을 보였다고 한다.
input token을 처리하는 파라미터의 수가 minstral 7x8b 가 라마2 70b에 비하여 1/5 가량인데도 우월한 성능을 보인다는 것은 꽤나 인상적이다.
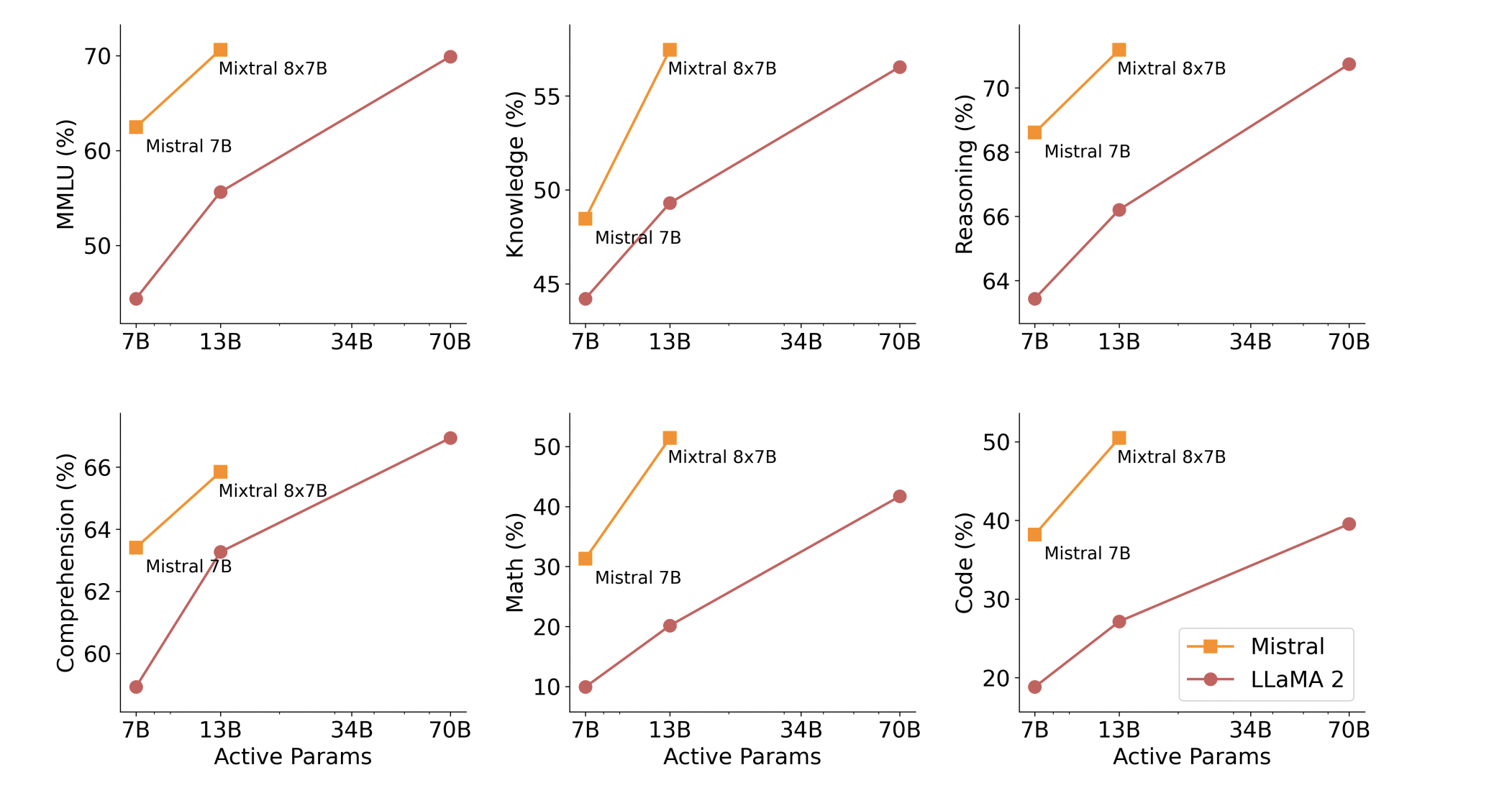
다만 같은 논문에서 비용 대비 성능적인 면에서의 효율성은 추론시에 해당하는 것이지 memory cost 는 전체 파라미터 수에 비례한다고 한다. 또한, 라우팅 메커니즘 등으로 인해 device utilization 면에서 부가적인 overhead 가 발생한다고도 하니 비용적인 면에서 MoE 의 타당성을 검토할 시 모델을 운용하는데 있어 전체적인 측면을 봐야할 필요성이 있다.
참고
- Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed
(2024, 01 08). Mixtral of Experts. Retrieved from arxiv: https://arxiv.org/abs/2401.04088 - Bergmann, D. (2024, 04 05). What is mixture of experts? Retrieved from IBM: https://www.ibm.com/topics/mixture-of-experts
- Sanseviero, O., Tunstall, L., Schmid, P., Mangrulkar, S., Belkada, Y., & Cuenca, P. (2023, 12 11). Mixture of Experts Explained. Retrieved from Hugging Face: https://huggingface.co/blog/moe
What is mixture of experts? | IBM
Mixture of experts (MoE) is a machine learning approach, diving an AI model into multiple “expert” models, each specializing in a subset of the input data.
www.ibm.com
Mixture of Experts Explained
Mixture of Experts Explained With the release of Mixtral 8x7B (announcement, model card), a class of transformer has become the hottest topic in the open AI community: Mixture of Experts, or MoEs for short. In this blog post, we take a look at the building
huggingface.co
Search | arXiv e-print repository
Showing 1–2 of 2 results for author: Sayed, W E arXiv:2401.04088 [pdf, other] cs.LG cs.CL Mixtral of Experts Authors: Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego d
arxiv.org
'IT Note > Data&AI' 카테고리의 다른 글
| 생성형 AI 개발 정상화해줬잖아 개발까지 다 해줬잖아 (Feat 클로바 스튜디오) (0) | 2024.09.08 |
|---|---|
| Hadoop Basics (1) | 2024.08.01 |
| Quantum 말고 Quant! (0) | 2024.05.19 |
| 호다닥 톺아보는 VectorDB 기초 (0) | 2024.05.18 |
| [생성형AI 해볼게요] 생성형 AI로 포스터 만들어볼게요 (Midjourney, WatsonX, ChatGPT, Canva) (0) | 2024.05.17 |



