원문 : 호롤/Hadoop Basics
Overview
사실 이 글을 쓰는 2024년에는 너무나도 당연하게 모르면 안될 용어가 되어버린 "빅데이터"...
ChatGPT가 떠오르면서 AI에 너도나도 큰 관심이 쏠리게되고, 거기에 더불어 Data 영역도 화두가 되었습니다.
Data없이 AI를 논할 수는 없기 때문입니다.
이번 포스팅에서는 꽤나 초기 플랫폼이지만 아직까지 여러 회사에서 많이 사용되고 있는 "Apache Hadoop"에 대해서 알아보도록 하겠습니다.
빅데이터란?
그 전에 먼저 빅데이터가 무엇인지 짚고 넘어가야겠죠!
빅데이터는 단순히 "큰 사이즈의 데이터"를 의미하기도 하지만 넓은 의미로는 큰 사이즈의 데이터로부터 가치를 추출하고 Insight를 얻어내는 것 으로 정의할 수 있습니다.
SNS의 등장과, 보급된 여러 전자기기로부터 발생하는 데이터가 기하급수적으로 많아졌고,
그에 따라 메모리 가격의 인하로 대용량의 데이터를 저장하기 용이해졌으며,
분산 병렬처리 기술의 발달로 이 대용량의 데이터 분석이 가능해졌습니다.
데이터의 형태로는
CSV와 같이 Column단위 구분자와 명확한 형태가 존재하는 정형데이터,
정형화된 구조가 없는 비디오, 오디오, 사진과 같은 비정형데이터,
정형데이터와 같이 테이블의 Column단위로 구조화되어있지는 않으나, 스키마나 메타데이터 특징을 가지고 있는 반정형데이터 (ex. XML, HTML, JSON등)
세가지로 나뉘게 됩니다.
그러나 세상만사 예측할 수 없는만큼 정형데이터보다는 비정형, 반정형 데이터가 압도적으로 많습니다.
그래서 수집된 데이터들을 다양한도구를 사용하여 정형형태로 변형하고 분석에 사용하는 경우가 많습니다.
Hadoop이란?
그래서 비즈니스 운영 전반에 걸쳐 폭발적으로 증가하는 이 비정형 데이터들을 기존의 RDB기술로는 처리하기 힘든 경지에 도달하였고, 대용량의 데이터를 적은 비용으로 빠르게 분석할 수 있는 플랫폼의 필요성이 대두되기 시작했습니다.
거기서 등장한 노란코끼리가 바로 Apache재단에서 만든 Hadoop이라는 녀석입니다.

하둡은 빅데이터의 처리와 분석을 위한 플랫폼 으로,
하나의 성능 좋은 서버를 이용해 데이터를 처리하는 대신에 여러개의 범용 서버들을 클러스터화 하고, 대용량의 데이터를 처리하는 오픈소스 프레임워크라고 보시면 됩니다.
Hadoop Ecosystem

하둡의 코어 프로젝트는 아래에서 후술할 HDFS, MapReduce등이 있지만, 그 외에도 다양한 서브 프로젝트들이 있습니다.
워크플로우 매니지먼트, 데이터마이닝, 수집, 분석 등등 하둡을 좀 더 편하고 쉽게 이용할 수 있게 여러 서브프로젝트들이 있고 이 모임을 하둡 에코시스템이라고 부릅니다.
이번 포스팅에서는 하둡의 코어프로젝트중 HDFS와 MapReduce 만 서술하도록 하겠습니다.
HDFS (Hadoop Distributed File System)

하둡 코어 프로젝트 중 가장 큰 프로젝트이며, 하둡의 기본 스토리지 시스템입니다.
- 자바기반의 분산 확장 파일 시스템
- 여러 노드에 파일을 나눠서 저장함, 여러 서버에 데이터를 중복해서 저장함으로써 데이터 안정성을 확보
- HDFS에 파일을 저장하거나 조회하려면 스트리밍방식으로 접근해야함
- 한번 저장된 데이터는 수정할 수 없음, 읽기만 가능 (데이터 무결성)
- 2.0부터 저장된 데이터에 append할 수 있는 기능 추가
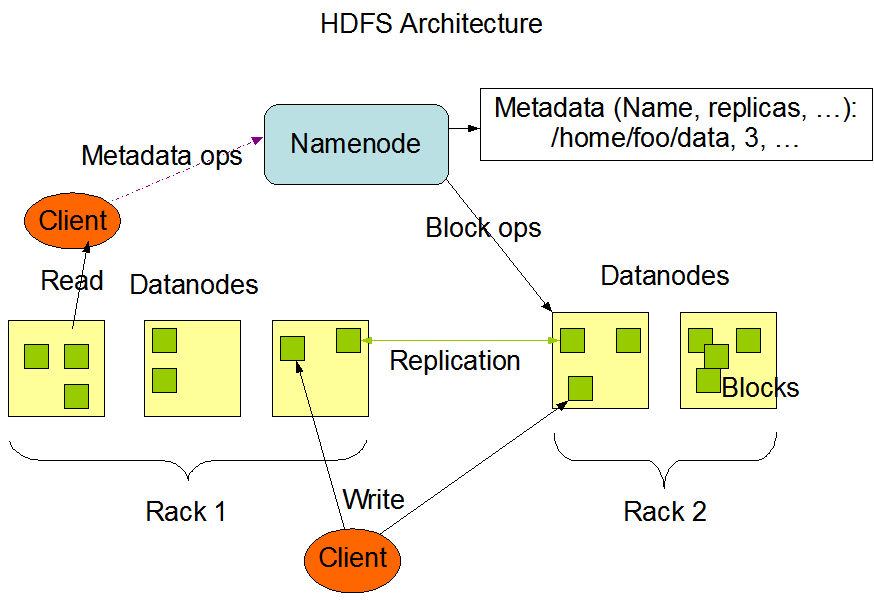
- Master/Slave구조를 가짐, 명칭은 네임노드/데이터노드
- Name Node : 메타데이터 관리, 데이터노드 관리
- Fsimage 파일: 네임스페이스, 블록정보
- Edits 파일: 파일 생성/삭제 트랜잭션 로그
- 2버전에는 Namenode가 1개였는데 3버전부터 HA지원(recommended 3node)
- Data Node : 실제 파일을 저장하는 역할, 파일은 블록단위로 저장됨
- Block : 데이터가 읽히고 쓰여지는 가장 작은 단위, HDFS에서 블록의 사이즈는 default 128MB
- 실제 파일 크기가 블록 사이즈보다 작은 경우, 파일 크기만큼만 디스크를 사용함
- Replication : Fault-tolerant하게 파일들의 블록을 (Default)3번 복제하여 각 노드에 저장
- Namespace : HDFS는 전통적인 파일 계층 구조를 지원함(폴더트리), 파일 블럭에 접속할 수 있는 경로를 의미 (ex. /path/to/file.txt)
- Metadata : 블럭 자체의 정보 (생성일시 등)
HDFS file write flow
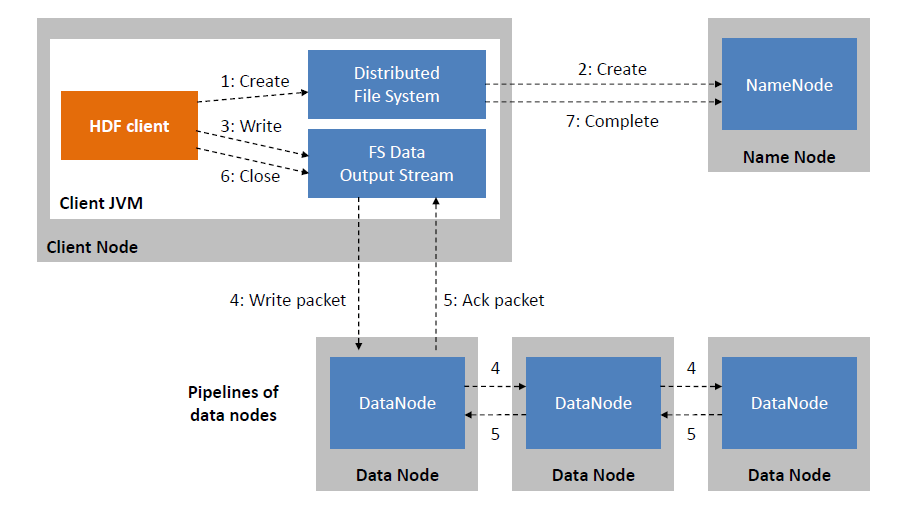
- HDFS클라이언트는 Distributed File System의
create()함수를 호출해 파일 생성을 요청 - NameNode는 생성될 파일이 이미 있지 않은지, Client가 적절한 permission을 가지고 있는지 체크한 후, NameNode 메모리에 파일의 경로 정보를 생성하고 lock
그 후, NameNode는 파일을 저장할 DataNode를 선택해서 host정보를 client로 반환 - Distributed File System은 클라이언트가 파일을 생성할 수 있도록
FSDataOutputStream을 반환하고, 데이터를 으로 분할하고 큐에 저장
큐에 저장된 패킷은 네임노드에 의해 새로운 블럭으로 할당 - Replication의 설정에 따라 블럭의 복제본이 DataNode에 저장
일단 NameNode에서 받은 DataNode목록의 첫번째 노드에 데이터를 보내고,
파이프라인에 따라 첫번째 노드가 두번째 노드로 데이터를 전달하는 방식으로 복제본의 수만큼 데이터가 저장 FSDataOutputStream은 DataNode의 승인 여부를 기다리는 ack큐를 유지하고 파이프라인 내 모든 DataNode로부터 ack응답을 받아야 완료- 데이터 write를 완료하면 client는
close()메소드를 호출 - 모든 패킷이 완전히 전송되면 NameNode에 파일 쓰기 완료 신호를 보내서 동작을 완료시킴
HDFS file read flow
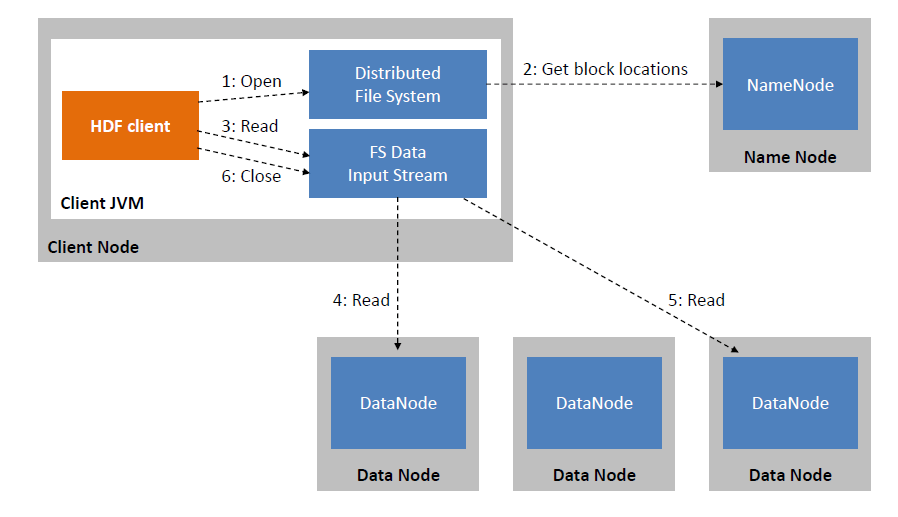
- 클라이언트는 Distributed File System에서
open()호출 - Distributed File System은 파일의 첫번째 블록 위치를 파악하기 위해 NameNode호출
- NameNode는 데이터의 메타데이터를 갖고 있기 때문에 저장된 블록들의 위치를 알고있음,
이에 해당하는 Datanode의 주소를 반환하고 네트워크 위상에 따라 클라이언트와 가까운 순서대로 DataNode들이 정렬,
그 다음 Distributed File System은 클라이언트가 데이터를 읽을 수 있도록FSDataInputStream을 반환 - 파일의 첫번째 블록이 저장된 DataNode에서 데이터를 전송
- 첫번째블록의 전송이 끝나면
FSDataInputStream은 데이터노드의 연결을 닫고 다음 블록의 데이터 노드를 찾아서 읽음 - 모든 블록에 대한 읽기가 끝나면
FSDatainputstream의close()를 호출해서 연결을 끝냄
Hadoop Map Reduce

HDFS에서 분산파일시스템으로 대용량의 데이터들을 저장하였으니, 이제는 이 파일들을 분산/병렬 컴퓨팅 환경에서 처리하기 위한 데이터 처리 모델이 필요할겁니다.
Hadoop Map Reduce는 대규모 분산 컴퓨팅 환경에서 대량의 데이터를 병렬로 분석할 수 있게 해주는 분산 프로그래밍 프레임워크입니다.
크게 정렬된 데이터를 분산처리(Map)하고 이를 다시 합치는(Reduce)과정을 수행하는 프로세스로 이뤄져있습니다.
주요 컴포넌트 :
Job Tracker : Map&Reduce 작업이 수행되는 전체 과정을 관리
Task Tracker : 작업에 대한 분할된 Task를 수행, 실질적 Data Processing의 주체
Map
분산 프로그래밍을 위한 프레임워크이니만큼 각 단계는 하나 이상의 Mapper와 Reducer를 실행해 작업을 하게 됩니다.
Map 단계에서는 각 데이터들을 일괄 "처리"하고 Key-Value 형식으로 리스트를 반환하게 됩니다.
여기서 "처리"는 어떤 것이든 될 수 있습니다.
가령 각 데이터들의 텍스트를 대문자로 변환할 수도 있구요,
class Mapper
method map(string k,string v)
Emit(k.toUpper(), v.toUpper())
=> ('foo', 'bar') -> [('FOO', 'BAR')]텍스트의 단어 개수를 세어보는 것도 생각해볼 수 있겠습니다.
class Mapper
method Map(docid a, doc d)
H ← new AssociativeArray
for all term t ∈ doc d do
H{t} ← H{t} + 1
for all term t ∈ H do
Emit(term t, count H{t})
=>
('1', 'a a a bb a ccc') -> [(a,4),(bb,1),(ccc,1)]
('2', 'a a a bb a a bb bb bb') -> [(a,5),(bb,4)]
('3', 'a bb a ccc ccc ccc') -> [(a,2),(bb,1),(ccc,3)]
참고 : Basic MapReduce Algorithm Design, Birkbeck University of London
Shuffle
Map -> Reduce로 넘어가기 전에 한번 매핑된 출력값들이 정렬되고 통합되는 단계를 거칩니다.
유사한 값들은 그룹화되고 중복된 값은 폐기되어 깔끔한 형태로 Reducer에 전달되게 됩니다.
예를 들어 위에서의 단어 개수는 동일한 key값끼리 합쳐져 아래와 같이 정렬될 것입니다.
(a, [4, 5, 2])
(bb, [1, 4, 1])
(ccc, [1, 3])Reduce
Map단계에서 처리가 끝난 key-value형태의 리스트를 받아 원하는 데이터를 추출하는 단계입니다.
예를 들어서, 위의 예제에서 추출했던 단어들의 총 합을 구해볼 수도 있을겁니다.
class Reducer
method reduce(term t, counts[c1, c2,...])
sum ← 0
for all count c ∈ counts [c1, c2,...] do
sum ← sum + c
Emit(term t, count sum)
=>
(a, [4, 5, 2]) -> (a, 11)
(bb, [1, 4, 1]) -> (bb, 6)
(ccc, [1, 3]) -> (ccc, 4)Example - word count
위의 pseudo code로 예제를 들었던 단어개수세기 작업을 도식화해보겠습니다.
Hadoop MapReduce라고 검색하면 열의 아홉은 이 예제를 예시로 들고 있는데, 그만큼 이 알고리즘을 직관적으로 이해하기 쉬워서 그런 것 같습니다.
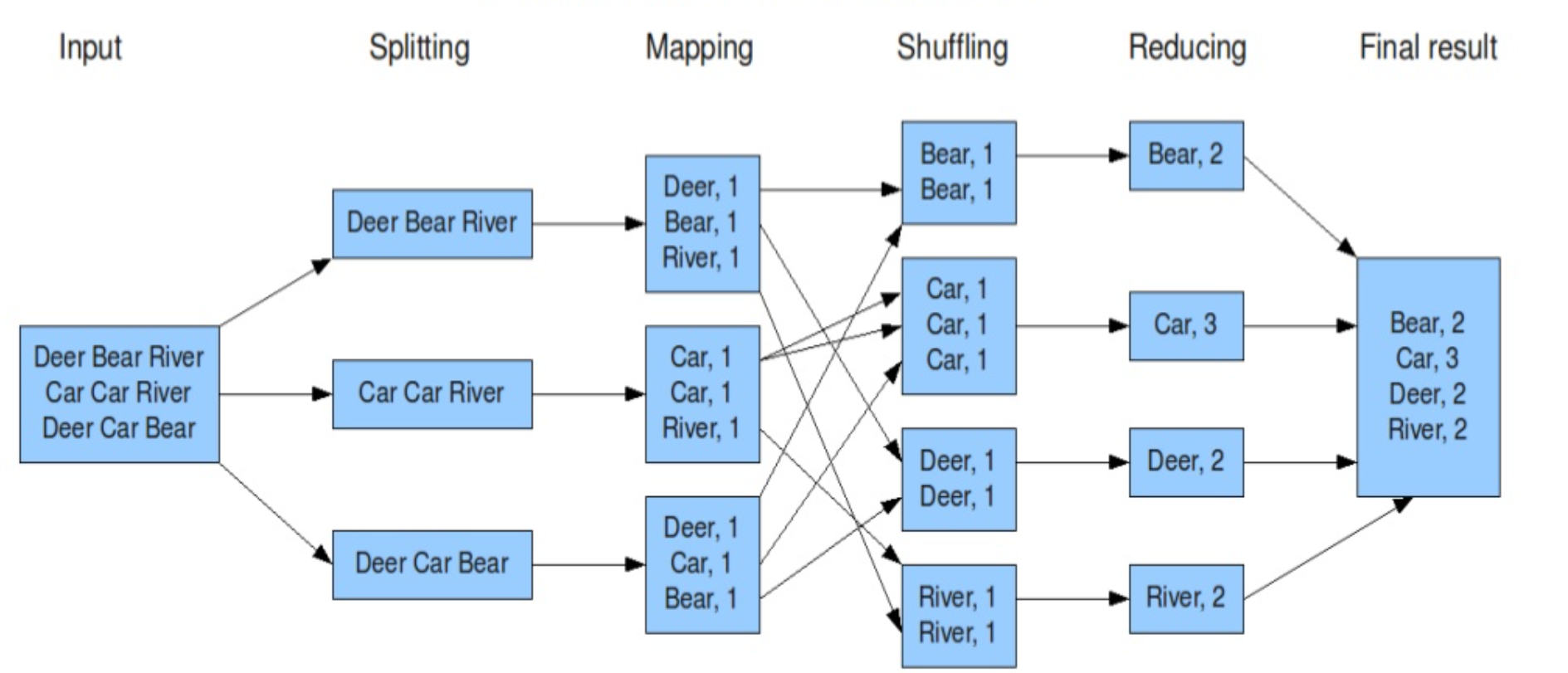
- 텍스트파일을 HDFS에 업로드하고, 각각의 파일은 블록단위로 나눠져서 저장됨
- Splitting : 블록안의 텍스트파일을 한 줄로 분할
- Mapping : 공백기준으로 쪼개고, 각단어의 발생횟수를 계산한 뒤, Key-Value형식으로 리스트를 반환 (sorting, grouping작업이 용이하기때문)
- Shuffling : 연관성 있는 데이터들끼리 모아서 정렬, Reduce phase를 수행할 노드로 분산하여 전송
- Reducing : 특정 단어가 몇 번 나왔는지 계산
- 이후 결과를 합산하여 HDFS에 파일로 저장된다
정리하면 엄청나게 큰 작업을 분할해서 작은 작업들로 만들고, 작은 작업들을 여러 Mapper들로 병렬처리한 후 나온 결과들을 Reducer들로 합쳐 최종 결과를 도출하는 방법이라고 보시면 됩니다.
'IT Note > Data&AI' 카테고리의 다른 글
| 호다닥 톺아보는 데이터저장소 친구들(feat. DB,DW,DL,LH) (1) | 2024.10.08 |
|---|---|
| 생성형 AI 개발 정상화해줬잖아 개발까지 다 해줬잖아 (Feat 클로바 스튜디오) (0) | 2024.09.08 |
| Mixture of Experts (MoE) ? 그게 뭔데...어떻게 하는 건데... (3) | 2024.05.19 |
| Quantum 말고 Quant! (0) | 2024.05.19 |
| 호다닥 톺아보는 VectorDB 기초 (0) | 2024.05.18 |



