1. 모니터링 왜함?
지금 시대는 비트코인, 주식, NFT, 선물 등 1초마다 가격이 요지부동 하는 도파민 범벅 무침의 시대입니다.
(저는 홀덤을 좋아합니다.)

이 상품들의 특징들은 1초마다 Price가 달라진단 겁니다.
하루 죙일 그래프만 보고 있어도 시간이 아주 잘갑니다.

이런 가격들은 수요와 공급법칙이든 이상 법칙에 의해 이루어진다 하더라도 누군가는 그래프에 이 가격을 띄워야 합니다.
1분 이상 서버가 멈춘다 ? 저부터 오함마 준비해서 키움증권이든 업비트든 뛰어갈 것 같습니다.
선물과 디파이같은 파생상품이 즐비하는 시대에 자기 돈이 1분이든 1시간이든 플랫폼에 묶여있다면 미칠 노릇이겠죠

이런 애플리케이션의 중단 등을 막고 혹은 중단 되었더라도 빠르게 상황을 파악해서 문제를 해결하기 위해서라도 모니터링은 필수요소입니다.
2. 보통 어떻게 함?
그래서 서버의 중단이 비즈니스 퍼포먼스에 엄청난 영향을 주는 기업의 경우에는 어딜가나 엄청 큰 전광판을 띄워놓고 보고 있습니다.
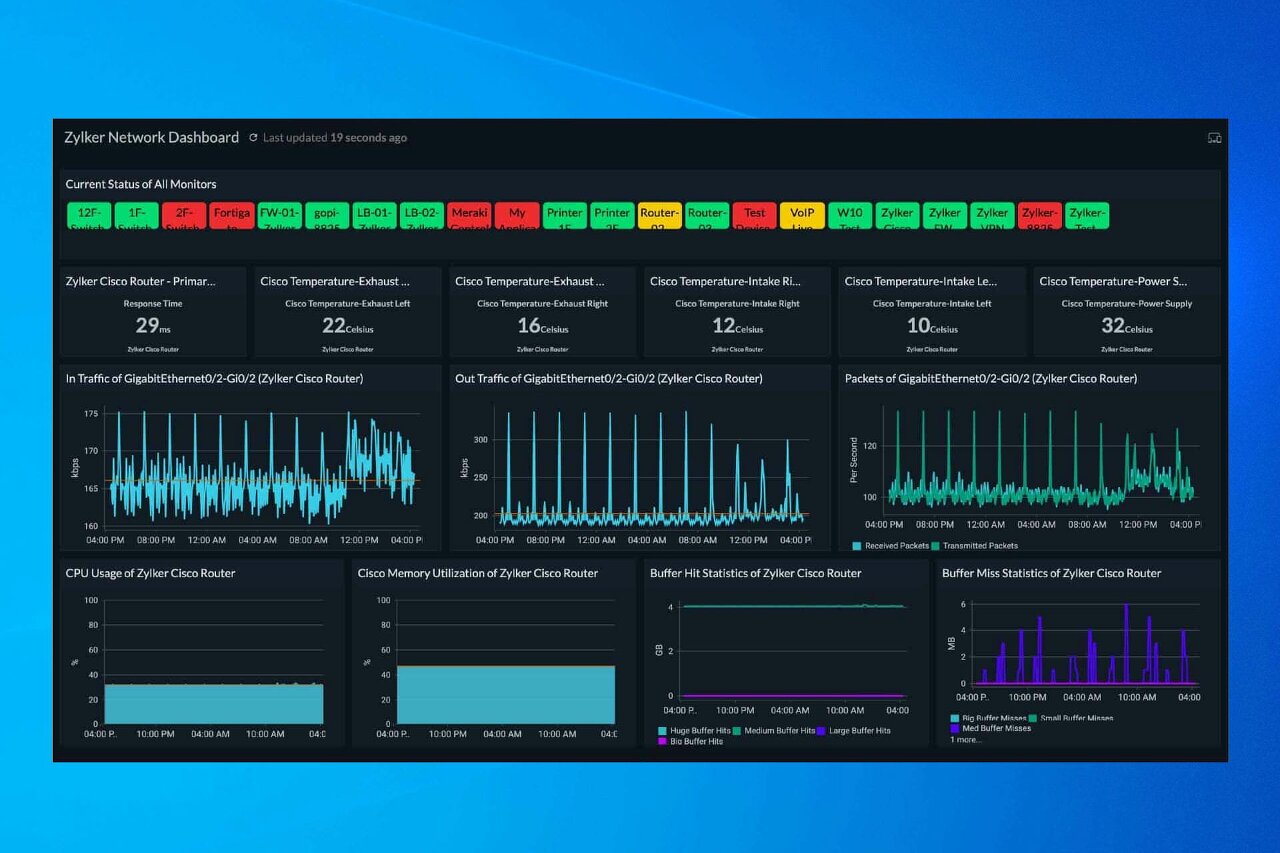
Cloud는 기본적으로 서버를 중앙에 집적화해놓고 빌려쓰기 때문에 이 모니터링에 관련해 더 민감합니다.
1초의 중단이나 딜레이가 엄청나게 비즈니스에 영향을 주는 기업들이 자사 중요서버들을 Cloud로 안쓰는 이유이기도 합니다.
Window에서는 ctrl+alt+delete로 작업관리자를 볼 수 있고 CPU / RAM 점유율 및 Disk Usage에 대해 볼 수 있습니다.
아주 일반적인 사용자도 볼 수 있는 이 지표는 무엇을 의미할까요?
컴퓨터에서 제일 중요한 지표라는 뜻입니다.
사양이 높은 게임을 할때 좋은 사양을 가진 컴퓨터를 사는 것은 그 게임을 무중단, 프레임이 끊기지 않게 하고 싶기 때문입니다.
아주 큰 컴퓨터인 서버도 지향하는 바가 똑같습니다.

클라우드는 사양 좋은 컴퓨터를 논리적으로 쪼개서 사용합니다. 많이 쪼갤수록 이득이죠.
하지만 논리적으로 컴퓨터를 쪼갤수록 부하가 걸릴 수 밖에 없습니다.
밥먹으면서 게임만 해도 힘든걸요..
3. 왜 프로메테우스?
이렇게 부하체크를 하고 중단을 막거나 문제해결을 하기 위해 가장 인기있는 클라우드 오픈소스 제품이 Prometheus 이 녀석입니다.

사실 모니터링 제품은 엄청 많습니다.

여기에서 Prometheus + Grafana 조합이 인기가 많은 이유는 OpenSource이기 때문입니다.
한번 설치해보겠습니다.
Step 1. 사전구성환경
| Node | OS | CPU | RAM | IP |
| Master | Centos | 4 Core | 4096MB | 192.168.50.11 |
| Node1 | Centos | 2 Core | 2048MB | 192.168.50.54 |
| Node2 | Centos | 2 Core | 2048MB | 192.168.50.143 |
| Prometheus용 서버 | Centos | 2 Core | 2048MB | 192.168.56.204 |
Proxmox를 VM 환경으로 사용해 구성하였습니다.

Step 2. Firewall 해제
Node_exporter는 9100 port를
Prometheus는 9090 port를 사용하므로 반드시 해제해줘야 노드간 통신이 가능합니다.
### Firewall에 Prometheus 서비스 추가 ###
[root@localhost ~]# firewall-cmd --permanent --add-service=prometheus
success
### Firewall에 Node exporter를 신규 서비스로 등록 ###
[root@localhost ~]# firewall-cmd --permanent --new-service=node_exporter
success
### Firewall에 Node exporter의 포트정보 등록 ###
[root@localhost ~]# firewall-cmd --permanent --service=node_exporter --add-port=9100/tcp
success
### Firewall에 Node exporter 서비스 추가 ###
[root@localhost ~]# firewall-cmd --permanent --add-service=node_exporter
success
### Firewall에 적용 ###
[root@localhost ~]# firewall-cmd --reload
success
### Firewall에서 적용상태 확인 ###
[root@localhost ~]# firewall-cmd --list-services
cockpit dhcpv6-client grafana node_exporter prometheus ssh구성
Step 3. Prometheus 설치
wget https://github.com/prometheus/prometheus/releases/download/v2.36.0/prometheus-2.36.0.linux-amd64.tar.gz
tar xvfz prometheus-*.tar.gz
cd prometheus-*Step 4. yaml 파일 수정
Worker 1과 Worker 2를 Target 으로 Join 시키는 것이 목적이기에 Node_exporter의 9100포트를 기본으로 부여했습니다.
[root@prometheus prometheus-2.36.0.linux-amd64]# cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
- job_name: 'node'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['192.168.50.54:9100', '192.168.50.143:9100']
labels:
group: 'production'Step 5. Node_exporter 설치
wget https://github.com/prometheus/node_exporter/releases/download/v*/node_exporter-*.*-amd64.tar.gz
tar xvfz node_exporter-*.*-amd64.tar.gz
cd node_exporter-*.*-amd64
./node_exportercurl http://localhost:9100/metrics
curl 명령어로 metrics 가 잘 받아져 오는지 확인할 수 있습니다.
Step 6. Browser로 확인
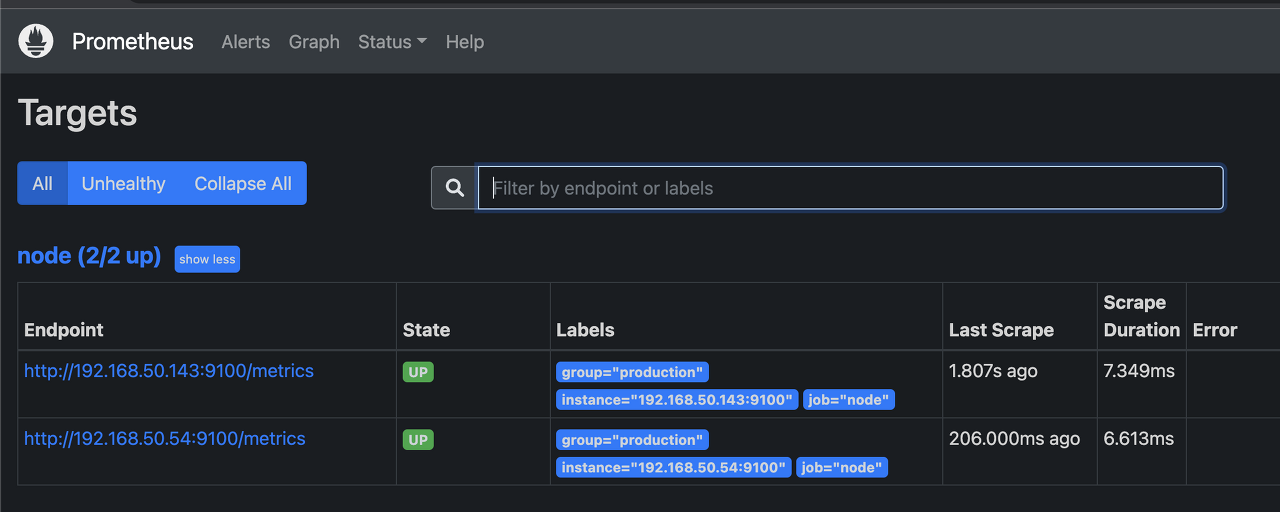
타겟이 잘 붙은것을 확인할 수 있습니다.
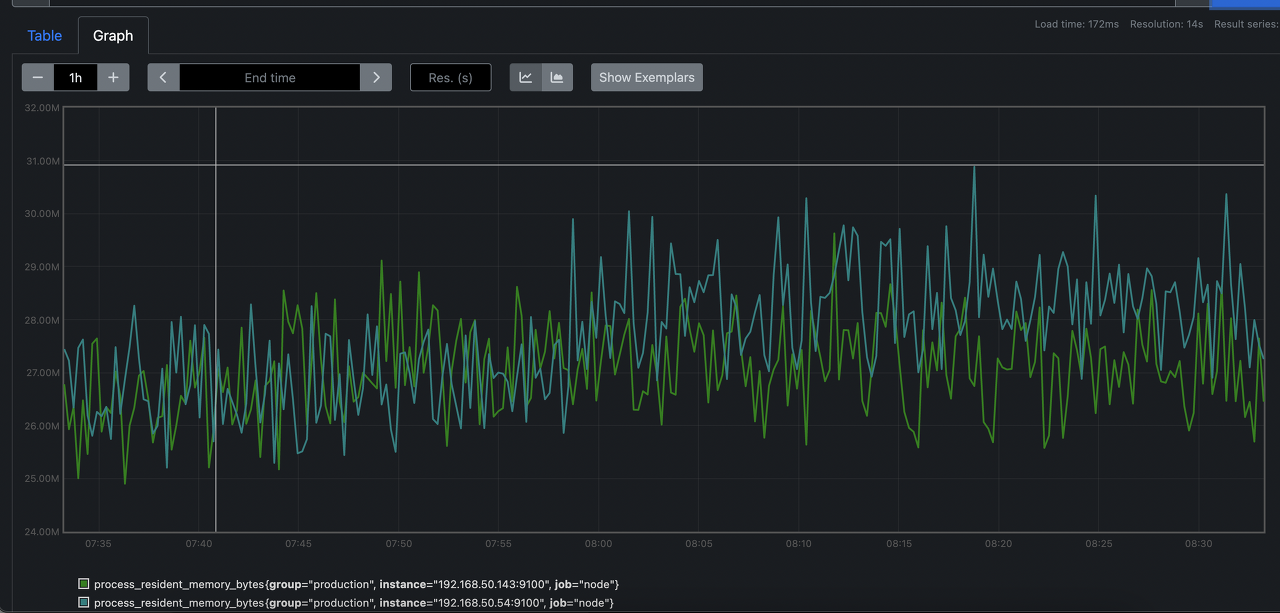
prometheus는 기본적으로 graph를 지원하기에 node들의 사용량을 체크해 볼 수 있습니다.
'IT Note > Cloud' 카테고리의 다른 글
| 금융 클라우드, 자 드가자~ (Feat. Naver Cloud) (2) | 2024.09.07 |
|---|---|
| 2023 금융분야 클라우드컴퓨팅 이용가이드 요약하기-1 (0) | 2023.10.31 |
| [1분 IT] MultiCluster Monitoring에 대해 알아보기... 근데 실습을 곁들인 (1) | 2023.01.23 |
| Tekton이란? (0) | 2021.06.09 |
| Kubernetes Cluster Upgrade (0) | 2021.05.24 |


