원문 : 호롤리/Query Optimization (feat. watsonx.data)
Overview
Query Optimization의 개념과, IBM의 lakehouse 솔루션인 watsonx.data에서 어떻게 쿼리 최적화를 할 수 있는지 알아보도록 하겠습니다.
Environment
Openshift : 4.16.x
CP4D : 5.0.3
watsonx.data : 2.0.3
Query Optimization
두 개의 쿼리가 항상 순서 상관없이 같은 튜플들을 반환한다면 그것은 동등하다고 볼 수 있습니다.
예를 들어서 :
Natural Join (join순서를 어떻게 하던 동일한 결과를 반환합니다.)
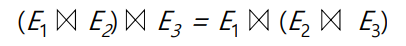
Select 연산 (만약에 E1테이블에서만 select 조건에 부합하는 튜플들이 있다면 먼저 select를 하고 join하든 테이블끼리 join하고 select를 하든 결과는 동일)
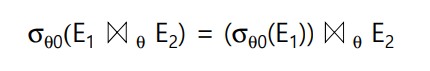
이런식으로 동등한 결과를 반환하기 위해 여러 쿼리의 조합을 고민해볼 수 있는데, 이들 중 최적의 쿼리를 찾아서 연산시간을 줄이는 것을 Query Optimization이라고 합니다.
그럼 Query Optimization은 어떤 방식으로 연산시간을 줄일까요?
RBO(Rule-Based Optimizer)
- 미리 정해둔 규칙에 따라 쿼리를 최적화
- SQL구문(JOIN, WHERE 등)에 대한 고정 규칙을 적용
- 인덱스 구조나 비교 연산자에 다른 순위여부를 기준으로 최적의 경로를 찾는다
-> 명확한 규칙이 존재하여 어느정도 실행순서와 결과를 예측할 수 있지만 최적화에 대한 깊은 이해 없이 효과적인 규칙을 만들기 쉽지 않음.
그리고 몇개의 규칙만으로 모든 상황에 대응하기는 쉽지 않다.
CBO(Cost-Based Optimizer)
- 쿼리 수행하는데 소요되는 비용을 기반으로 최적화
- 테이블, 인덱스, 컬럼 등의 오브젝트 통계정보 + CPU, Disk I/O 등 시스템 통계정보까지 사용
- 통계정보가 정확하지 않거나 최신 데이터가 아니라면 잘못된 최적화를 할 수도 있다 (예측어려움)
CBO 기반 Query Optimizer 구성요소
각 Query Optimizer마다 조금씩 프로세스가 다를테지만, 대략 아래와 같은 프로세스를 거칩니다.
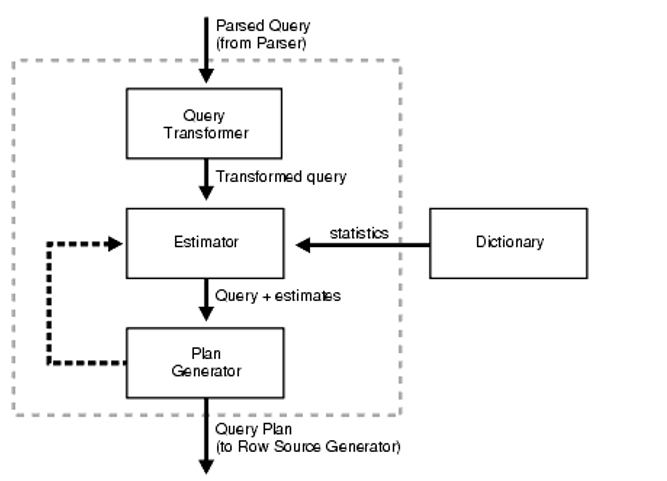
Parser
SQL을 파싱해서 파싱 트리를 만들고 문법오류나 의미상의 오류를 체크
Query Transformer
파싱된 쿼리블럭들이 더 효율적으로 처리할 수 있는 동등한 쿼리로 만들어지는게 유리한지 여부를 결정함
예를 들어 테이블 두개가 있는데
create table test1(a number primary key);
create table test2(a number primary key references test1(a));test1테이블은 a컬럼이 primary key이고,
test2테이블의 a컬럼은 test1의 a컬럼을 foreign key로 참조하는 동시에 primary key입니다.
그래서 test1테이블의 모든 row는 test2에 있게됩니다.
이런 상황에서 Inner join query를 하고 select query를 하는 쿼리를 transformer에 보내봅시다.
select count(*) new_name_for_hard_parse_01
from test1
join test2 on test1.a = test2.a;생각해보면 test1의 모든 row가 test2에 포함되므로 inner join이 필요없고, 그냥 test2테이블에서 select하면 됩니다!
(inner join은 두 테이블의 교집합만 뽑아냄)
실제 transformer의 결과를 트레이스 파일에서 확인해보면 요런식으로 join없이 test2에서 select하는걸로 바뀌어있습니다.
...
Final query after transformations:******* UNPARSED QUERY IS *******
SELECT COUNT(*) "NEW_NAME_FOR_HARD_PARSE_02" FROM "JHELLER"."TEST2" "TEST2"
....
예시 출처 : stackoverflow/How can I see the query that the query transformer produced in Oracle
Estimator
오브젝트와 시스템 통계정보를 활용해서 쿼리 수행시 Selectivity(쿼리에서 선택되는 행 집합의 비율, 0은 없음 1은 모든 행), Cardinality(각 연산이 반환하는 row의 개수), Cost(연산에 필요한 리소스)를 기반으로 총 비용을 계산함
Plan generator
다양한 경우의 수의 조합을 통해 쿼리 블록에 대한 plan을 생성.
optimizer는 cost가 가장 낮은 plan을 선택
Query Optimization in watsonx.data
그럼 지금부터는 IBM의 lakehouse 솔루션인 watsonx.data의 Query Optimization 기능을 실습해보겠습니다.
주의사항
)watsonx.data의 Query Optimization 기능은Db2의 Query optimization기능을 빌려와서 사용합니다.
*) 241128기준 Query Optimization기능은watsonx.dataUI에서 동작하지 않습니다! UI에서는 session변수를 지정해줄 수 없기 때문입니다.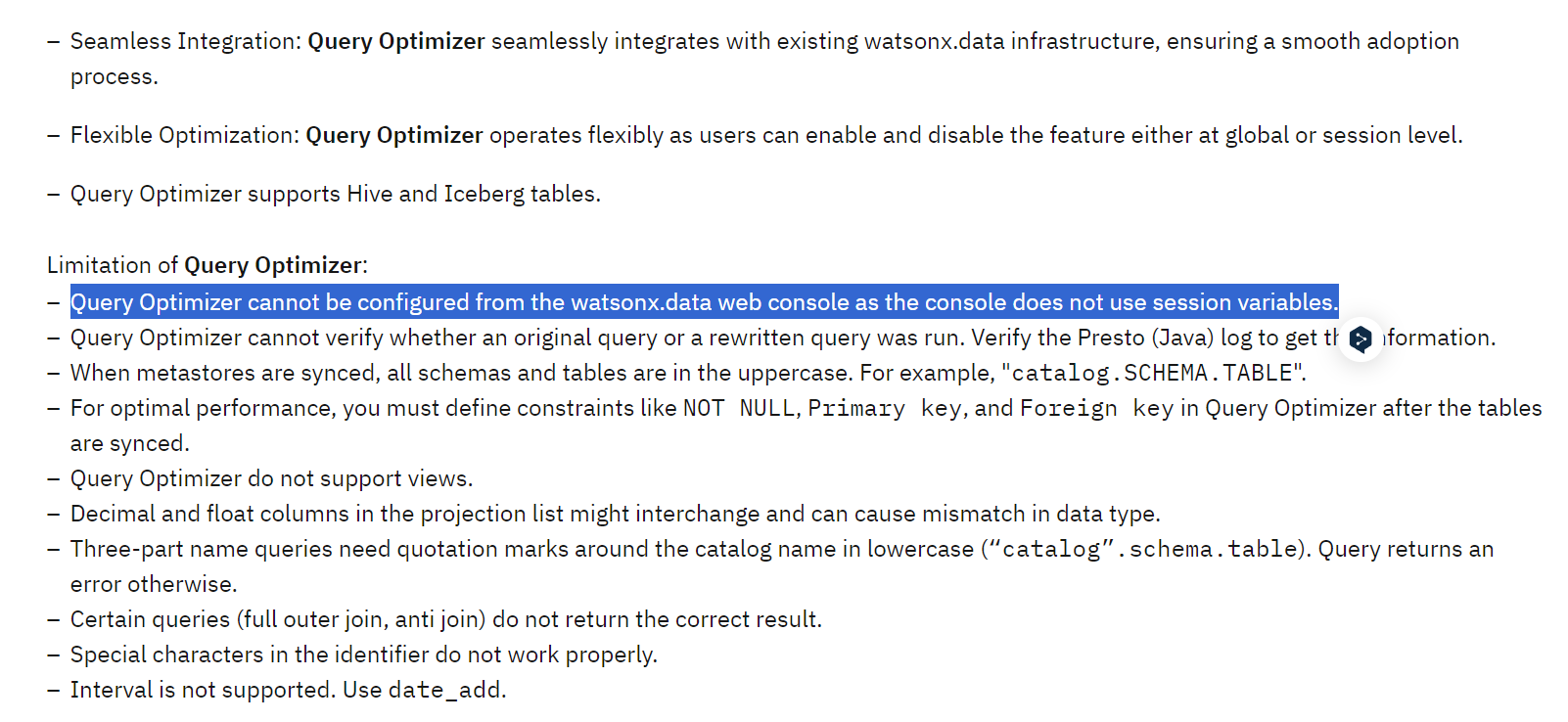
1. ibm-lh client 설치
$ bin/presto-cli --version
Presto CLI 0.286-44efa192. Query Engine 등록
쿼리엔진 java나 c++등록하고 아래 링크의 절차를 따라 Query optimization기능을 활성화시켜줍니다.
->
활성화가 완료되고 나서, presto cli가 설치된 서버로 돌아옵니다.
그 다음 Query Optimization기능이 활성화된 엔진을 서버에 등록해줍니다.(host는 https빼고)
예제에서 사용하는 엔진은 presto C++엔진입니다.
$ ./manage-engines --op=add --name=prestissimo288 --host=ibm-lh-lakehouse-prestissimo288-presto-svc-xxx.apps.xxx.com --port=443 --username=xxx --password=xxx
registering engine prestissimo288 ..
registered prestissimo288.3. Lakehouse 인스턴스 등록
다음으로 레이크하우스를 등록해줍니다. (여기서는 host에 https붙임)
$ ./ibm-lh config add_cpd --name lakehouse --host https://cpd-cpd-inst-operands.apps.xxx.com/ --port 443
{'component': 'config', 'action': 'add_cpd', 'name': 'lakehouse', 'host': 'https://cpd-cpd-inst-operands.apps.xxx.com/', 'port': '443'}
Config file updated with Host : https://cpd-cpd-inst-operands.apps.xxx.com/ and Port : 4434. 등록된 인스턴스 리스트 확인
$ ./ibm-lh config ls
{'component': 'config', 'action': 'ls'}
Listing all your Lakehouse Instances :
---------------
Name = lakehouse
Type = CPD
Host = https://cpd-cpd-inst-operands.apps.xxx.com/
Port = 4435. Certificate 등록
이거 안해주면 presto cli돌릴 때 에러납니다...
에러메세지 :
Error running command: javax.net.ssl.SSLHandshakeException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target아래 명령어를 통해 간단하게 인증서를 등록해줄 수 있습니다.
./cert-mgmt --op=add --host=ibm-lh-lakehouse-prestissimo288-presto-svc-cpd-inst-operands.apps.xxx.com --port=443
...
Certificate was added to keystore
ibm-lh-lakehouse-prestissimo288-presto-svc-cpd-inst-operands.apps.xxx.com:443, Oct 14, 2024, trustedCertEntry,
Certificate fingerprint (SHA-256): ***
/mnt/infra/tls/truststore.jks updated.6. presto-cli 실행해보기
인증서까지 등록을 마쳤다면 이제 테스트용 presto 쿼리를 실행해보도록 하겠습니다.
먼저 간단한 샘플 sql파일을 작성해주고
SELECT
"c_name"
FROM
"tpch"."sf1"."customer"
LIMIT
10;sql 파일의 폴더 환경변수를 지정해줘야 합니다(필수)
export LH_SANDBOX_DIR=<path to sql-files>쿼리 실행!
./presto-run --engine=cpadmincpp --session enable_wxd_query_optimizer=false -f $LH_SANDBOX_DIR/test.sql
"Customer#000037501"
"Customer#000037502"
"Customer#000037503"
"Customer#000037504"sql파일 없이 간단하게 쿼리를 실행해보고 싶다면 :
$ ./presto-run --engine=cpadmincpp --session enable_wxd_query_optimizer=false --catalog=tpch <<< "select * from tiny.customer limit 10;"
presto> select * from tiny.customer limit 10;
c_custkey | c_name | c_address | c_nationkey | c_phone | c_acctbal | c_mktsegment | c_comment
-----------+--------------------+-----------------------------------------+-------------+-----------------+-----------+--------------+---------------------------------------------------------------------------------------------------------------------
626 | Customer#000000626 | cnMmU,52YaSUMLxNvi1 | 5 | 15-540-121-5663 | 5447.12 | FURNITURE | quickly ironic ideas. deposits will nag quickly slyly even requests. carefully stealthy r
627 | Customer#000000627 | yclsr1Ie2I0Zgz ,XaYDqom7oC8B | 15 | 25-811-790-3533 | 5826.68 | FURNITURE | gular requests. ironic requests above the regular deposits are at the pending packages. regular theodoli
...7. Query Optimizer Log Property
제대로 쿼리가 최적화 되는지 여부를 로그로 확인하기 위해서 로그 프로퍼티 설정을 바꿔주도록 하겠습니다.
테스트하고자하는 엔진으로 접속:
$ oc exec -it ibm-lh-lakehouse-prestissimo288-coordinator-blue-0 bash내부에서는 vi나 vim이 없으므로 아래와같이 cat을 활용해서 프로퍼티 설정을 추가해줍니다.
bash-5.1$ cat >log.properties
com.facebook.presto=INFO
com.facebook.presto.governance=DEBUG
com.facebook.presto.governance.util=DEBUG
com.facebook.presto.dispatcher=DEBUGCtrl+d로 빠져나오면 됩니다.
그다음 런처를 재시작해주겠습니다.
bash-5.1$ cd /opt/presto/bin
bash-5.1$ ./launcher_restart_handler.sh restart8. 테스트용 데이터 추가
테스트용 데이터셋을 추가해주도록 하겠습니다.
뉴욕의 택시와 모빌리티를 관리하는 TLC에서 취합한 뉴욕의 trip record입니다.
yellow taxi와 green taxi의 일부 데이터만 추가해주도록 하겠습니다.
241128기준 presto c++에서는
TIMESTAMP를 인식하지 못하는 에러가 있어 drop시키고 진행함
9. Db2(Query Optimizer) 동기화
새로 등록된 테이블 정의와 Hive/Iceberg 통계데이터를 인식시키게 하기 위해 Query Optimizer기능을 갖고 있는 Db2 인스턴스와 wxdata의 메타스토어를 동기화시켜주어야합니다.
아래 경우에는 동기화 단계를 진행해주도록 합시다.
- 기존 테이블에 무언가 중대한 변경이 발생했을 경우
- 초기 동기화 작업 이후 새로운 테이블이 생성된 경우
- 손상된 카탈로그나 스키마의 메타데이터가 누락된 경우
먼저 watsonx.data의 certificate를 가져옵니다.
# oc get secret ibm-lh-tls-secret -o yaml | grep " ca.crt" | sed 's/ \+[.a-z]\+: //' | base64 -d
-----BEGIN CERTIFICATE-----
MIIDBDCCAeygAwIBAgIQUjMCdcnJ8K4eB6JoTeAr7zANBgkqhkiG9w0BAQsFADAc
...
ZPvq+pmL705A5KOfMfTtNVvtDvN/REmMr25drc4/Hd01Ox+PMXB2v74qLsbaP9Ni
F75eNow2AyQ=
-----END CERTIFICATE-----이걸 파일로 만들어서 db2 pod에 옮겨둡니다.
# oc exec -it c-lakehouse-oaas-db2u-0 -- bash
[db2uadm@c-lakehouse-oaas-db2u-0 /]$ vi /tmp/hms.pem그런 다음 GUI의 쿼리스페이스로 이동하여 아래 커맨드로 메타스토어를 등록해주고
ExecuteWxdQueryOptimizer 'CALL SYSHADOOP.REGISTER_EXT_METASTORE('<CATALOG_NAME>','type=watsonx-data,uri=thrift://<HMS_THRIFT_URI>,use.SSL=true,ssl.cert=/tmp/hms.pem,auth.mode=PLAIN,auth.plain.credentials=<ID:PW>', ?, ?)';example)
ExecuteWxdQueryOptimizer 'CALL SYSHADOOP.REGISTER_EXT_METASTORE('test_catalog','type=watsonx-data,uri=thrift://ibm-lh-lakehouse-hive-metastore-svc.cpd-inst-operand.svc.cluster.local:9083,use.SSL=true,ssl.cert=/tmp/hms.pem,auth.mode=PLAIN,auth.plain.credentials=username:password', ?, ?)';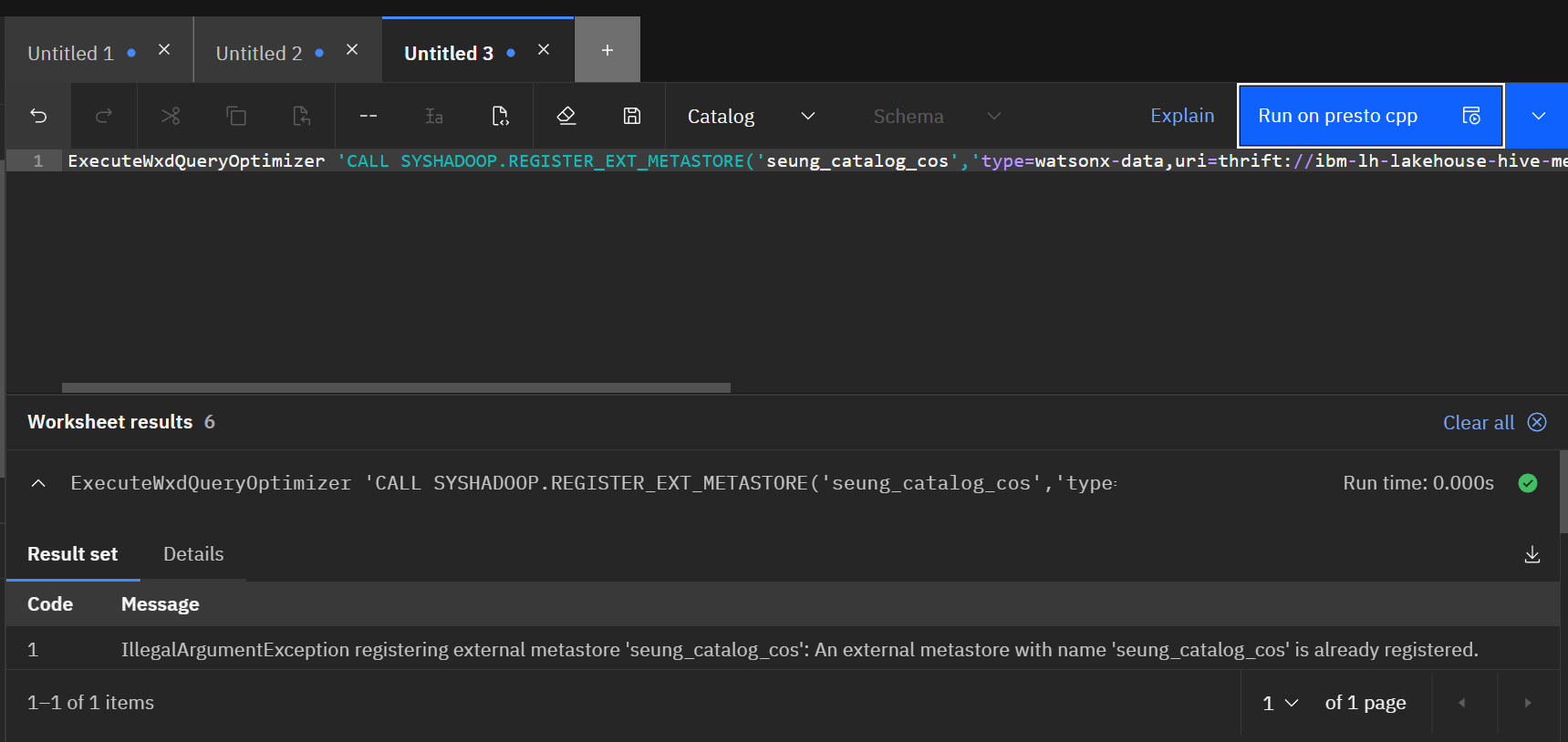
왜인진 모르겠는데 첫번째 시도에서는 에러가 나지만 두번째부터는 성공합니다.
다음으로 메타스토어 싱크를 맞춰줍니다!
ExecuteWxdQueryOptimizer 'CALL SYSHADOOP.EXT_METASTORE_SYNC('<CATALOG NAME>', '<SCHEMA NAME>', '.*', 'SKIP', 'CONTINUE', 'OAAS')';
반드시 스키마 이름은 모두 대문자로 적어주도록 합니다. Db2에 스키마가 저장될때는 대문자로 저장되기 때문입니다.
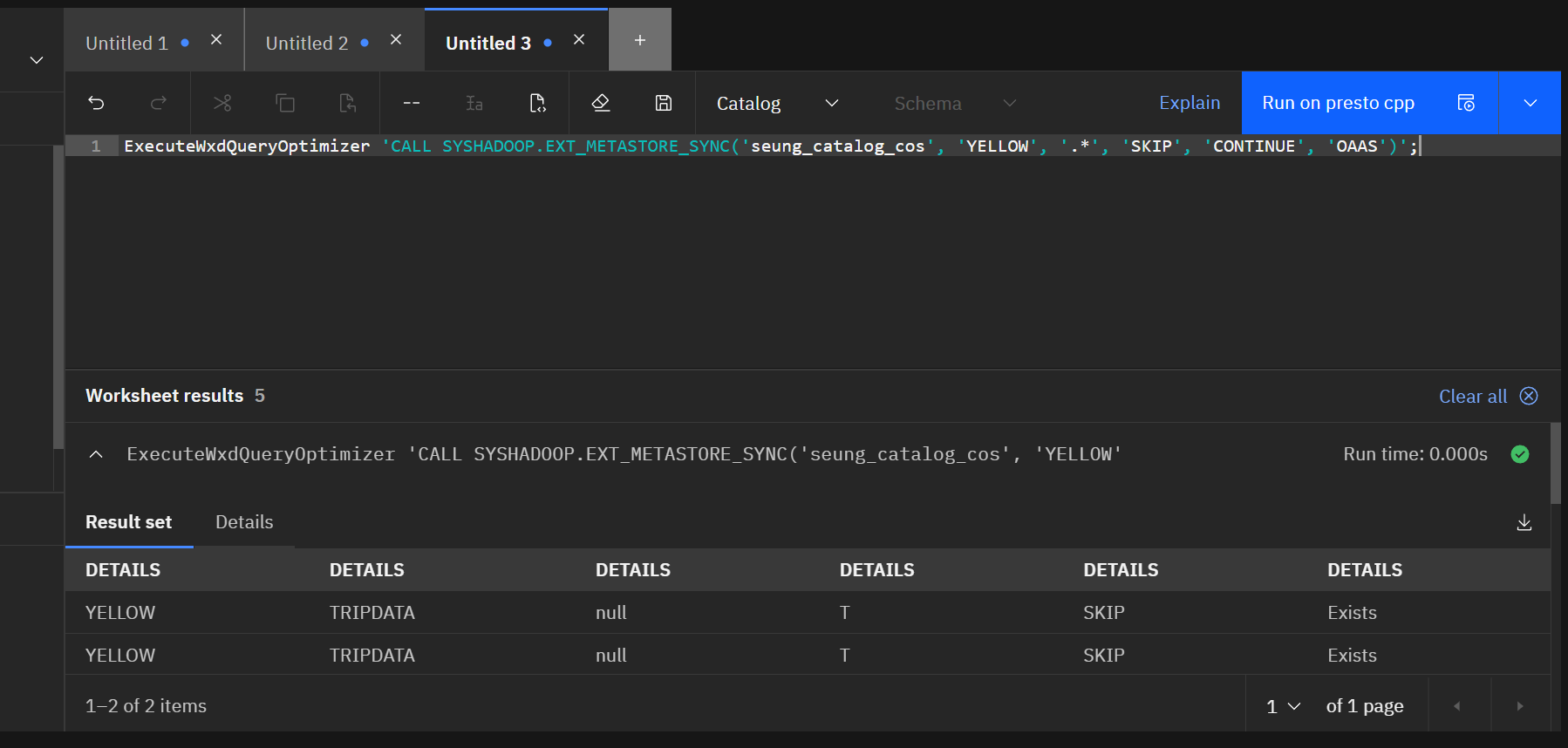
마지막으로 Statistic 정보들도 싱크를 맞춰주면 끝입니다.
ExecuteWxdQueryOptimizer 'CALL EXT_METASTORE_STATS_SYNC(
'<CATALOG_NAME>',
'<SCHEMA_NAME>',
'<TABLE_NAME>',
'<PRESTO_HOST>',
'<PRESTO_USER>',
'<PRESTO_PWD>',
'true'
)';example)
ExecuteWxdQueryOptimizer 'CALL EXT_METASTORE_STATS_SYNC(
'cos_catalog',
'GREENTAXI',
'TRIPDATA',
'ibm-lh-lakehouse-presto-01-presto-svc.cpd-inst-operands.svc.cluster.local:8443',
'username',
'password',
'true'
)';
왠진 모르겠지만 presto c++으로 설정하면 에러나는데 java는 정상적으로 동작합니다.
10. Query Optimizer 돌려보기!
뭔가 복잡한 쿼리 아무거나 만들어서 (ChatGPT가 잘만듭니다 :p)enable_wxd_query_optimizer=true옵션을 켜주고 실행해주겠습니다.
무언가 엄청 복잡한 쿼리가 나오고 optimization이 완료되었다는 로그를 확인할 수 있습니다.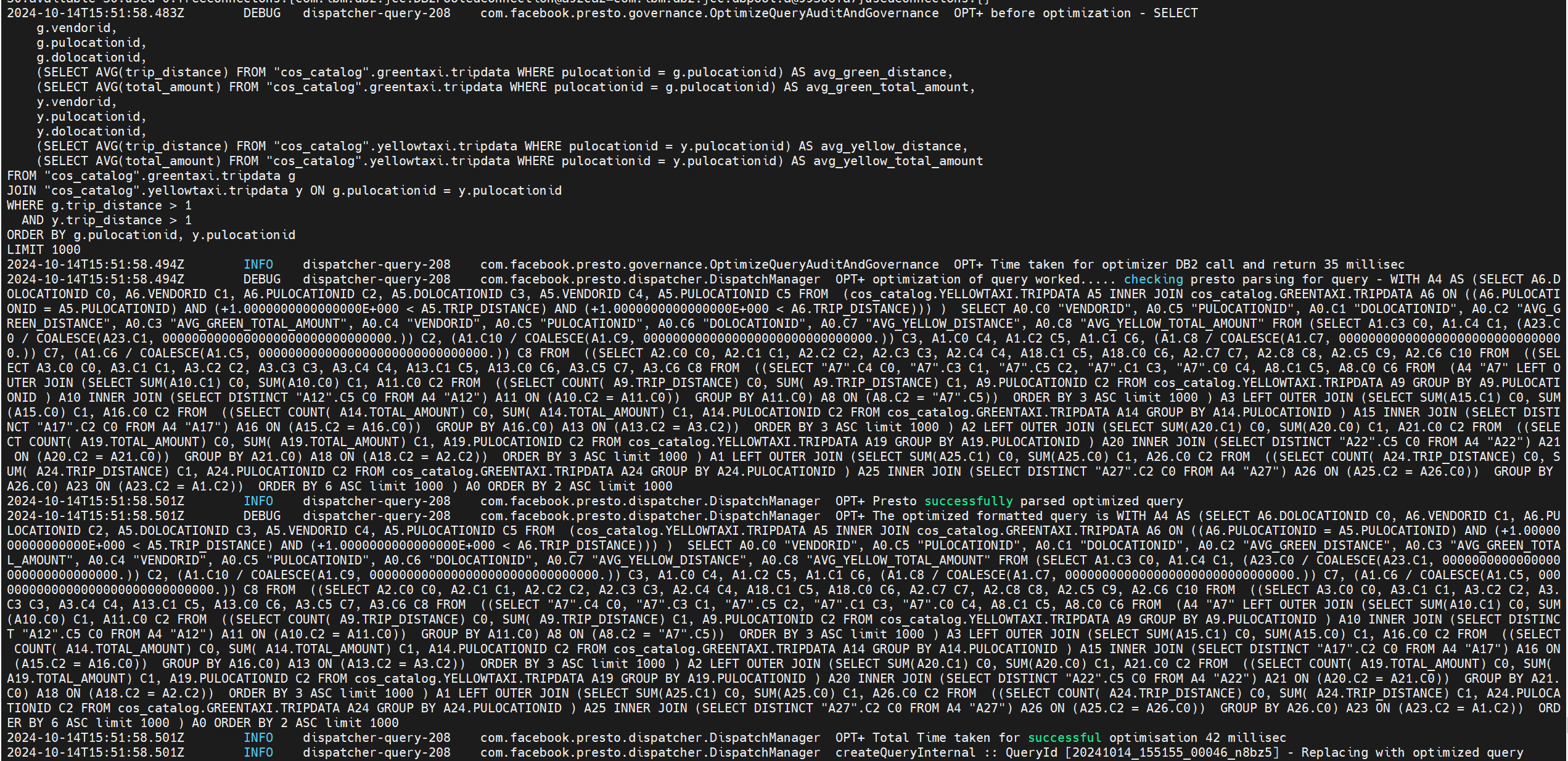
그리고 Presto의 Live Plan을 보면 원본과 최적화된 쿼리의 플랜이 달라진 것을 확인할 수 있습니다.
(원본 쿼리)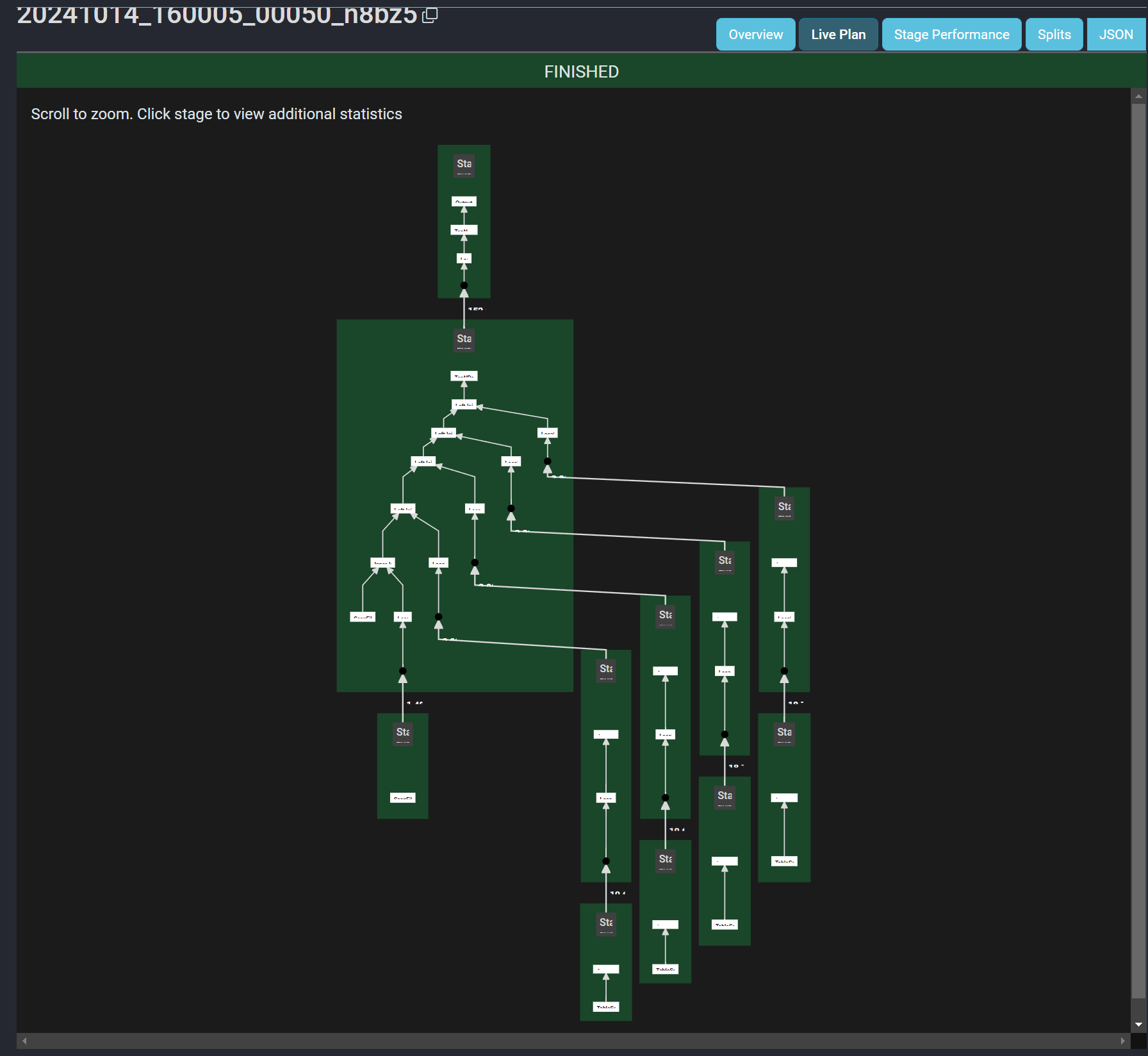
(최적화된 쿼리)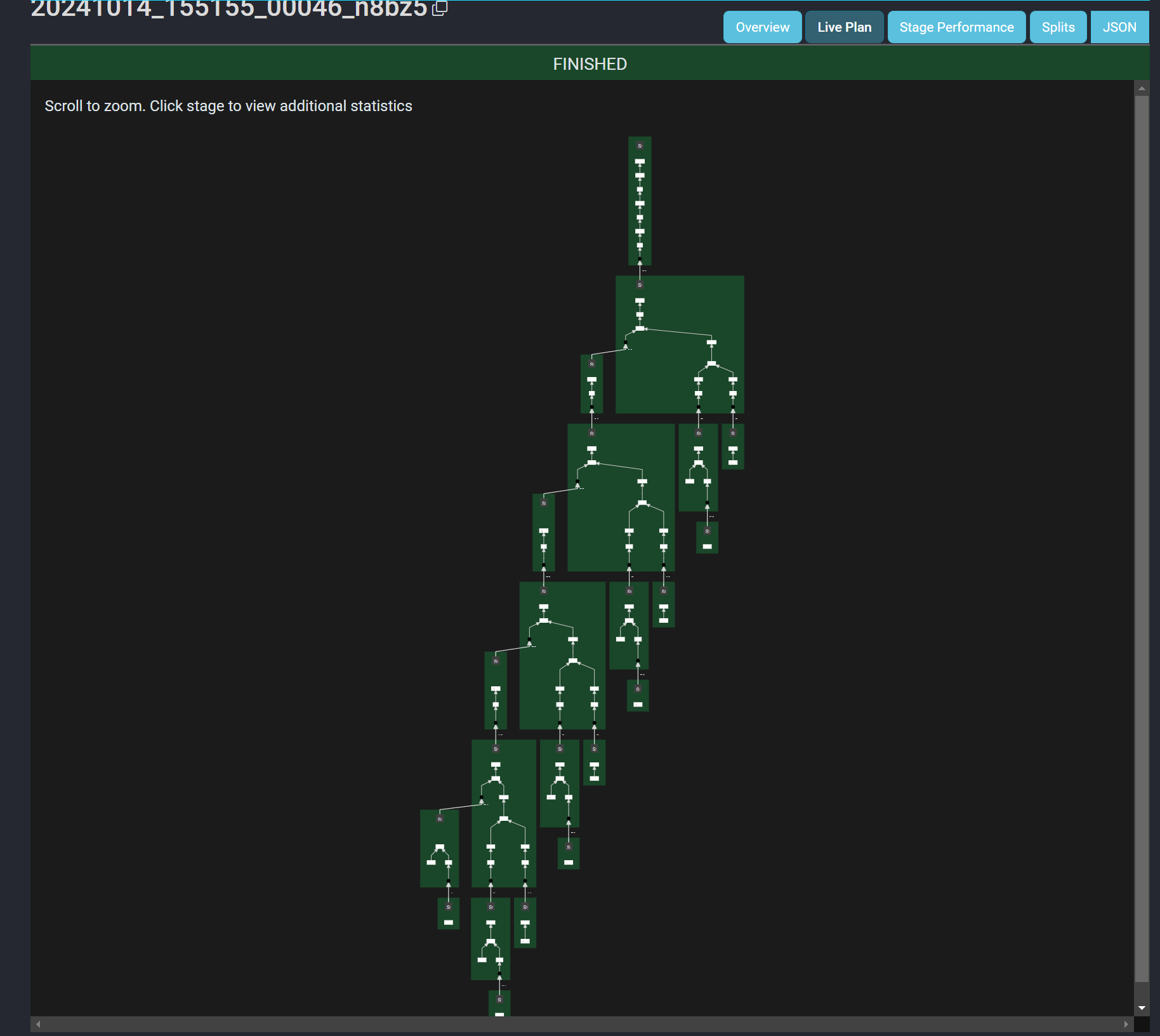
'IT Note > Data&AI' 카테고리의 다른 글
| Kafka의 필요성: 분산 데이터 환경의 필수품 (0) | 2024.12.15 |
|---|---|
| 국내 최초 CSAP SaaS 인증 공공솔루션 개발 네이버클라우드로 시작하기 (그런데 Redis를 곁들인..) (0) | 2024.12.14 |
| 제 1회 2024년 당근 테크 밋업에 갔다온 후기 (0) | 2024.10.20 |
| 호다닥 톺아보는 데이터저장소 친구들(feat. DB,DW,DL,LH) (1) | 2024.10.08 |
| 생성형 AI 개발 정상화해줬잖아 개발까지 다 해줬잖아 (Feat 클로바 스튜디오) (0) | 2024.09.08 |



